-
Jul 29, 2020
We explain the Nearest Neighbors algorithm. It follows from the idea of continuity that two datapoints that are close enough should have similar targets. We include a theoretical derivation, a description of the decision boundary, and a Python implementation from scratch.
-
Jul 15, 2020
We explain the theory of the expectation-maximization algorithm.
-
Jun 30, 2020
We explain in detail the Student's t-statistic and the chi**2 statistic.
-
Jun 20, 2020
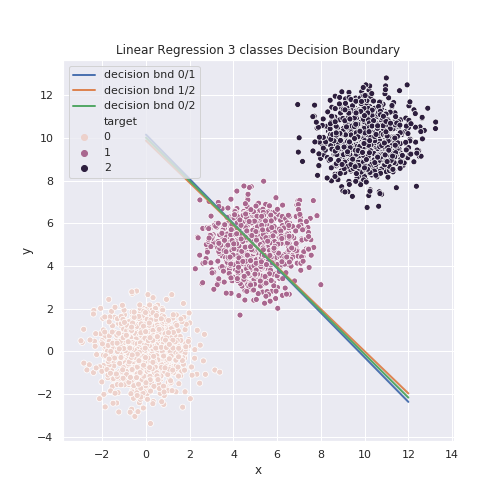
We explain the basics of linear regression and classification.
-
Jun 5, 2020
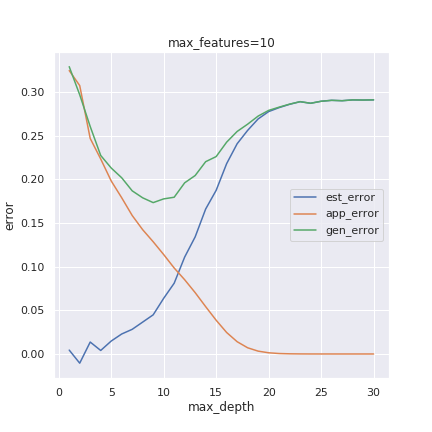
When fitting a model to the data, there is a tradeoff between bias and complexity. A less biased model can have higher complexity, but this also makes it more prone to overfit. In contrast, with more bias, the model is limited to simpler problems. We explain this phenomenon with python examples in both classification and regression examples.